Introduction
Xorq is an open source compute catalog for AI. It helps teams catalog, compose, reuse, and observe transformations, features, models, and pipelines across multiple engines.
Think of it this way: Apache Iceberg standardized data. Xorq standardizes compute.
What is Xorq?
Xorq is an open source compute catalog for reusing, shipping, and observing ML pipelines across multiple engines.
Data has standards like Iceberg and Delta. Xorq is the missing analog to Apache Iceberg, but for compute.
ML pipeline problems
Data infrastructure has standards. Iceberg and Delta solved how teams store and version data. But compute remains fragmented.
ML pipelines suffer from four problems:
- Leakage prone: Feature generation on historical data causes silent temporal leakage. Models train on information they should not have access to at prediction time.
- Disjointed: Pipelines communicate through runtime artifacts. Monitoring gets bolted on as an afterthought rather than built in from the start.
- Research-only: Features trapped in notebooks require complete rewrites for batch and online serving. What works in Jupyter fails in production.
- Undecipherable: ML pipelines become black boxes with no lineage or computation visibility. When something breaks, there is no way to trace back to the root cause.
These problems compound over time. A single invisible imputation in opaque preprocessing can run undetected for months, breaking model assumptions and invalidating predictions.
The solution: Xorq
Traditional approaches force a choice between the expressiveness of pandas and the scalability of SQL engines. This creates SQL-pandas impedance mismatches, wasteful recomputation, and pipelines that work in notebooks but fail in production.
Xorq provides a compute catalog with five core capabilities:
- Multi-engine workflows: Combine Snowflake, DuckDB, and Python in a single declarative pipeline. No engine-specific rewrites.
- Portable UDFs: Define user-defined functions once and run them across supported engines. Xorq serializes logic to YAML artifacts for reproducibility.
- Automatic caching: Cache intermediate results to avoid recomputing expensive joins after every change.
- Dev-to-prod consistency: A pipeline that works locally runs in production without code changes. Compile-time validation catches errors early.
- Built-in lineage: Automatic column-level lineage tracking and fail-fast execution provide visibility for production systems.
Core features
Xorq’s architecture provides six core capabilities that work together with:
- Deferred execution: Builds expression graphs before computation. Execution happens when explicitly triggered, allowing optimization of the full pipeline.
- Automatic caching: Caches intermediate results and invalidates cache when source data changes. Avoids unnecessary recomputation.
- Multi-engine execution: A single typed plan (YAML manifest) executes on DuckDB, Snowflake, DataFusion, BigQuery, Pandas, PostgreSQL, PyIceberg, and Trino.
- Content-addressed artifacts: Features, models, and pipelines are versioned by content hash. Identical computation produces identical hashes.
- Composable catalog: Catalog entries act as contracts between teams. Teams discover existing computations, compose on previous work, and share validated logic.
- Built-in governance: Column-level lineage tracking and compile-time schema validation. Policies enforce through compiled plans, not runtime checks.
Where Xorq fits
Xorq sits between your data sources and your ML applications. It’s not a replacement for your data warehouse or your model serving infrastructure, it is the layer that connects them.
The architecture image here illustrates this positioning. Expressions and UDFs flow through the manifest layer into stateless, Arrow-native execution across any supported engine.
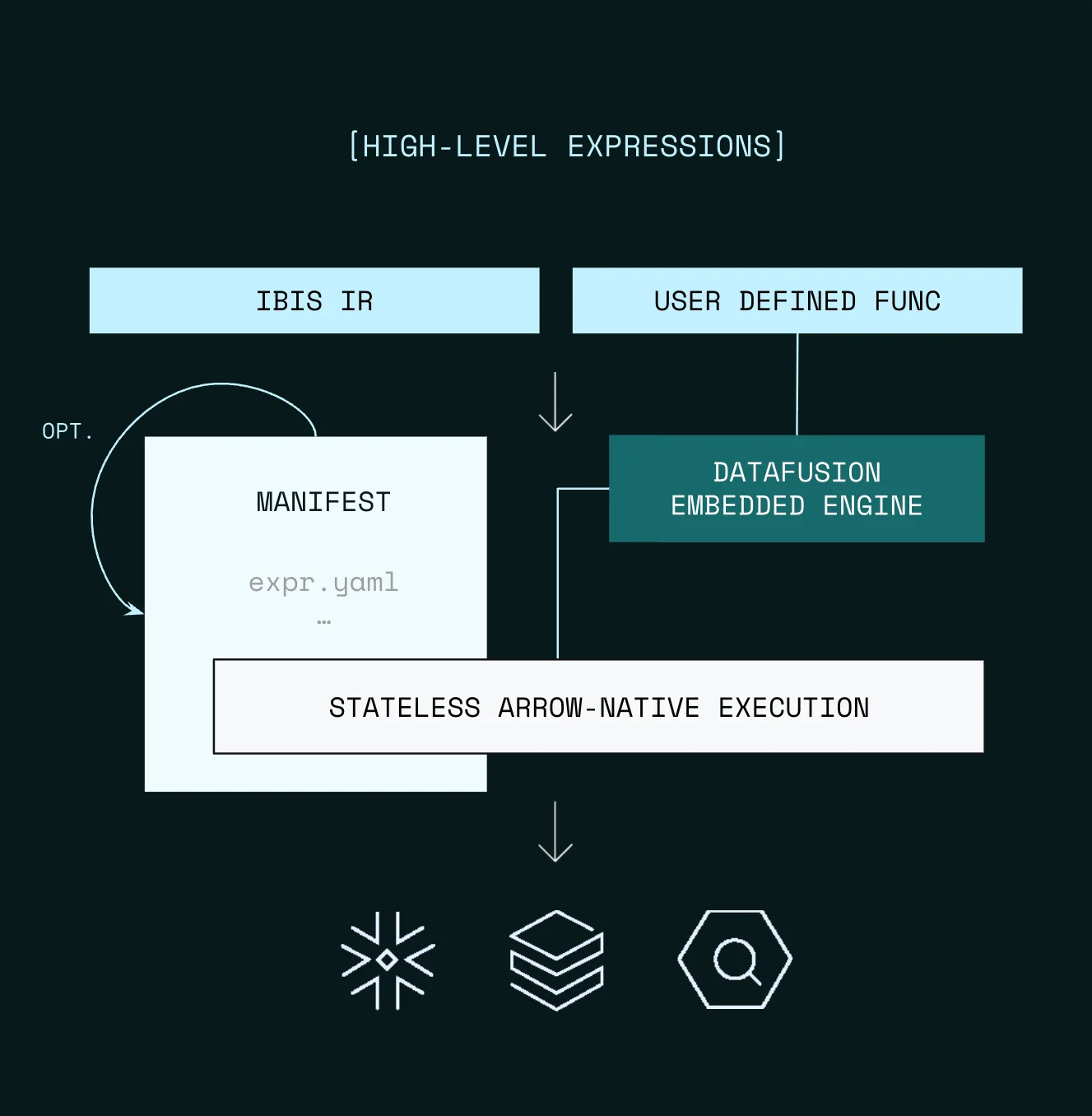
Teams use Xorq for feature stores, semantic layers, ML pipelines, batch scoring, and data CI. In each case, the value comes from the same properties: reproducibility, multi-engine portability, and full lineage.
Who Xorq is for
Xorq is designed for data scientists, data engineers, and ML engineers who:
- Work with SQL-heavy pipelines but need Python for ML.
- Run pipelines across multiple engines such as DuckDB locally and Snowflake in production.
- Need reproducibility and lineage for compliance or debugging.
- Want to share and reuse validated computations across teams.
If you are comfortable with pandas and SQL, then the Xorq API feels familiar.
Built on open standards
Xorq builds on battle-tested foundations:
- Apache Arrow Flight: Zero-copy data transfer between processes.
- Ibis: Cross-engine expression trees serialized to YAML.
- Apache DataFusion: Embedded engine for stateless Arrow-native execution.
- uv: Reproducible Python environment management.
The core expression and build logic remains open source.
Next steps
Now that you understand what Xorq is and why it exists, choose your path:
- Quickstart to build your first pipeline in under five minutes
- GitHub to star the repo and contribute
- Discord to join the community